- 创建代理池
- 环境
- 配置
- 使用
“
我们在做爬虫项目的时候经常需要做一些反爬措施,其中使用代理就是一个比较好的手段。今天我们就一起来学习一下如何搭建一个自己的爬虫代理池,当然重点是免费!最原始的方法肯定是我们自己单独去写一个爬虫来实现代理池的获取,这样做当然可以,但是作为一个标准的懒汉,我决定了使用大神们已经写好的项目来直接使用!
”
创建代理池环境- 本实例在Ubuntu20.04 python3.8的环境下完成!
- 项目需要使用到redis数据库,参考文章
- 按顺序执行下列代码
1.克隆项目到本地
https://github.com/jhao104/proxy_pool
2.安装依赖
pip3install-ihttps://pypi.doubanio.com/simple-rrequirements.txt
配置
- 修改项目的配置文件
#setting.py为项目配置文件
#配置API服务
HOST="0.0.0.0"#IP
PORT=5000#监听端口
#开放端口
$sudoufwallow5000#打开端口
$sudoufwenable#开启防火墙
$sudoufwreload#重启防火墙
#配置数据库
DB_CONN='redis://:pwd@127.0.0.1:8888/0'#redis有密码,0是数据库编号
DB_CONN='redis://:127.0.0.1:8888/0'#redis无密码,0是数据库编号
#配置ProxyFetcher
PROXY_FETCHER=[
"freeProxy01" #这里是启用的代理抓取方法名,所有fetch方法位于fetcher/proxyFetcher.py
"freeProxy02"
#....
]
- 启动项目命令
#如果已经具备运行条件 可用通过proxyPool.py启动。
#程序分为:schedule调度程序和serverApi服务
#启动调度程序
python3proxyPool.pyschedule
#启动webApi服务
python3proxyPool.pyserver
#一键启动
bashstart.sh
根据您自己的环境判断是否将start.sh脚本里面的python换成python3
- 注意:如果您使用的是python3.8在使用python3 proxyPool.py server的时候会出现一个如下报错
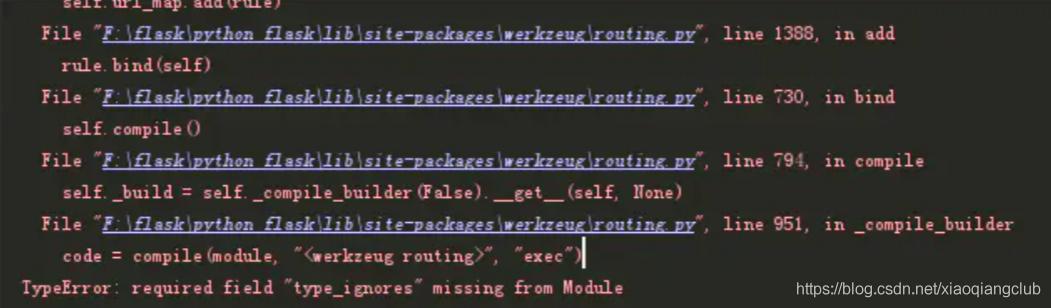
- 原因是python3.8的版本与werkzeug包的冲突
- 解决方案:直接进入这个包
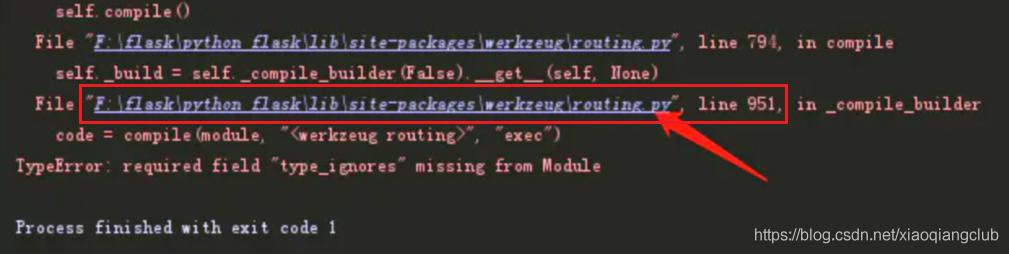
- 然后在950行的位置添加一个空列表,如下图:

- 然后重新运行python3 proxyPool.py server即可!
- 启动web服务后 默认配置下会开启 http://127.0.0.1:5000 的api接口服务:

- 爬虫使用案例(官方)
importrequests
defget_proxy():
returnrequests.get("http://127.0.0.1:5010/get/").json()
defdelete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
#yourspidercode
defgetHtml():
#....
retry_count=5
proxy=get_proxy().get("proxy")
whileretry_count>0:
try:
html=requests.get('http://www.example.com' proxies={"http":"http://{}".format(proxy)})
#使用代理访问
returnhtml
exceptException:
retry_count-=1
#删除代理池中代理
delete_proxy(proxy)
returnNone
〖特别声明〗:本文内容仅供参考,不做权威认证,如若验证其真实性,请咨询相关权威专业人士。如有侵犯您的原创版权或者图片、等版权权利请告知 wzz#tom.com,我们将尽快删除相关内容。
 微信扫一扫
微信扫一扫